
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- SQLD단기합격
- 천안방탈출
- 데이터시각화
- 천안데이트
- 데이터분석
- ADsP공부
- 태블로
- ADsP
- spting
- 비전공자SQLD독학
- mickito
- ADsP후기
- 백준
- Python
- SQLD독학
- 데이터분석준전문가
- sqld
- 자바
- SQLD노베이스
- listcomprehension
- Tableau
- SQL개발자
- 코딩테스트
- SQLD공부
- BOJ10951
- 방탈출
- 벡준1152
- 자율프로젝트
- 파이썬
- 머신러닝
- Today
- Total
목록Tableau (9)
doistory
 [Tableau] 태블로 계산된 필드
[Tableau] 태블로 계산된 필드
분석에 필요한 필드가 데이터 원본에 이미 포함되어 있지 않을 수도 있습니다. 이 때, 계산된 필드를 사용하면 데이터 원본에 이미 존재하는 데이터에서 새 데이터를 만들 수 있을 뿐만 아니라 데이터에 대한 계산을 수행할 수 있습니다. 이를 통해 복잡한 분석을 수행하고 데이터 원본에 고유한 필드를 즉석에서 추가할 수 있습니다. 1. 계산된 필드 - 숫자 예를 들어 데이터 원본에 “매출” 및 “수익” 값에 대한 필드는 있지만 “수익률”에 대한 필드는 없다고 가정합니다. 이 경우 아래와 같이 “매출”과 “수익” 필드를 사용하여 “수익률”이라는 계산된 필드를 만들 수 있습니다. 계산될 필드의 결과가 숫자일 경우 아이콘이 =# 라고 나타납니다. 계산된 필드 - 문자 계산된 필드 기능을 통해 숫자 뿐만 아니라, 조건문..
 [Tableau] 태블로 대시보드에서 뷰(워크시트) 필터 적용하기/필터링
[Tableau] 태블로 대시보드에서 뷰(워크시트) 필터 적용하기/필터링
태블로에서 대시보드 기능은 아주 유용하다. 별도의 그래픽 편집 프로그램이나 OA프로그램을 거치지 않고서 대시보드 기능을 활용해서 데이터를 시각화한 시트들을 배치하고 레이아웃을 조절하여 대시보드를 만들 수 있다. 위 대시보드는 전체 데이터에 대해 조회하고 있다. 개별시트에서도 시트마다 필터가 가능하지만 대시보드에서는 모든 워크시트전체 또는 복수의 워크시트에 필터를 적용 할 수 있어서 정말 유용하다. 수익성 문제가 발생한 '탁자'에 대해서만 지역별, 시계열별 자료를 보고싶거나 경기도의 '탁자' 제품에 대한 현황을 조회할 수 있다. 1. 먼저 필터가 전체 워크시트에 적용될 수 있도록 설정한다. 필터 옵션 > 워크시트에 적용 > 선택한 워크시트 > 적용할 워크시트 선택(전체 선택) 2. 그다음 각 워크시트를 필..
 [Tableau] 태블로 프렙 빌더를 이용하여 데이터 전처리 후 추출하기
[Tableau] 태블로 프렙 빌더를 이용하여 데이터 전처리 후 추출하기
태블로 프렙 빌더에서 데이터 분석을 위한 전처리를 수행한 화면이다. 태블로의 경우 코드를 작성하거나 SQL 쿼리문을 직접 짜지 않고 클릭으로 데이터 전처리 작업을 수행할 수 있다. [테이블 세로로 병합] 영업실적 2017 ~ 2020년의 데이터 파일이 excel 파일 형태로 년도별로 나뉘어있다. 파일들끼리 드래그 & 드롭 하여 유니온(union)할 수 있다. 이렇게 유니온을 이용하면 2017영업실적 아래에 2018년, 2019년, 2020년 데이터를 세로 방향으로 이어붙어 하나의 테이블로 만들 수 있다. [테이블 가로로 병합(join)수행] 그다음 앞에서 공부한 세로가 아닌 가로 방향으로 테이블을 연결할 수 있는데, 이때 SQL에서 JOIN개념을 이용하기 때문에 이름도 동일하다. 위에 그림에서도 유니온1..
 [Tableau] 태블로의 계산식: 행과 집계의 차이
[Tableau] 태블로의 계산식: 행과 집계의 차이
화면에 포함된 차원에 따라 측정값 또는 집계를 볼 수 있다. 상단 분석탭 -측정값 집계 옵션이 기본적으로 적용됨. 이걸 해제하여 풀어보면 아래와같이 측정값을 이루고있는 행 하나하나를 볼수 있다. 행수준 계산식과 집계수준 계산식의 차이점 비교 헹수준 계산식: 데이터 원본에 각각 하나하나행에 대해서 각각을 대상하고 그 계산 값이 이후에 집계(따라서 필드명이 그대로 쓰임) 각행에대해 계산되기에 실제로 그 값을 볼 수 있지만 오류: 계산에 오류있음 집계인수 및 집계되지 않은 인수를 이 함수와 혼합할 수 없습니다. 나타나는 이유 그냥 필드값(행수준)과 집계된 필드값(집계 수준 계산식)을 같이 사용하면 위와같은 에러 발생 행수준 계산식은 행수준 계싼식끼리, 집계 수준 계산식은 집계수준 계산식끼리 사용한다. 집계수준..
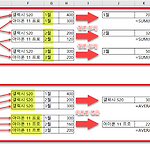 태블로 - 집계 (Aggregate)
태블로 - 집계 (Aggregate)
집계 (Aggregate) 집계는 측정값(숫자값)을 특정 기준(차원)으로 모으는 것을 의미합니다. 이때 반드시 집계 방법(합계, 평균, 최대값 등)이 지정되어야 하는데, 이를 집계 함수라고 합니다. 엑셀을 사용하여 집계가 이루어지는 과정을 개념적으로 설명한 예시를 살펴 보겠습니다. 위쪽의 합계와 아래쪽의 평균이 집계된 예시를 각각 상세하게 보면 다음과 같습니다. 1. 위쪽 예시 월별 합계 수량을 집계하는 과정을 보여줍니다. 각 월별 데이터를 모아서 엑셀의 SUM() 함수를 사용해서 집계한 결과를 볼 수 있습니다. 집계의 기준이 되는 월 이외의 차원은 집계 결과에서 보이지 않습니다. 2. 아래쪽 예시 제품별 평균 수량을 집계하는 과정을 보여줍니다. 각 제품별 데이터를 모아서 엑셀의 AVERAGE() 함수를..
 [Tableau] 태블로 워크시트 시각화
[Tableau] 태블로 워크시트 시각화
1. 폴더별 그룹화 : 불러와서 선택한 엑셀 시트(테이블)을 하나의 데이터셋으로 볼 수 있다. 데이터 원본 테이블 별 그룹화: 엑셀 각 시트별로 구분하여 볼 수 있다. 2. 폴더링 필드의 양이 많을 때 일부를 선택하여(shift+클릭) 우클릭 > 폴더링 할 수 있다. 폴더만들기 > 새로운 이름으로 폴더생성 ex) 고객정보들 = '고객'으로 폴더링, 제품 정보들 = '제품'으로 폴더링 (하단 사진 참고) 3. 퀵테이블 계산: 데이터 시각화를 하면서 자주 쓰는 함수 모음 4. 표현방식 차원과 측정값을 선택하면, 태블로가 알아서 그릴 수 있는 표현 방식을 선정해준다. 그 중 가장 권장되는 표현방식은 붉은 테두리로 표시된다.
 [Tableau] 태블로 데이터 '연결' 옵션
[Tableau] 태블로 데이터 '연결' 옵션
연결 옵션인 라이브와 추출을 toggle 옵션으로 선택 할 수 있다. 1. 라이브 데이터에 바로 연결하며 데이터 원본의 속도가 성능 결정 - 태블로에서 시각화에 필요한 sql문이 데이터베이스에 다이렉트로 질의를 던지고, 데이터베이스에서 질의를 처리하게됨. 처리된 결과물을 태블로에서 받아와 시각화가 이루어짐 - 실시간으로 데이터베이스에 쿼리를 던져 실시간으로 반영되는 데이터를 불러올 수 있음. - 추출과 달리 따로 새로고침 필요없이 live로 반영됨. - 데이터베이스 기반 2. 추출 추출에 모든 데이터가 포함 - 데이터성능이 좋지 않거나 용량이 클 때 사용한다. - 메모리 기반에서 데이터를 분석하고싶을 때 선택 가능한 옵션. - 실시간으로 쿼리를 던져 반영시키는 라이브와 달리 데이터가 새로고침 되는 시점에..
 [Tableau] 데스크탑 UI 구성 요소 및 명칭
[Tableau] 데스크탑 UI 구성 요소 및 명칭
1. 툴바 2. 표현방식 3. 데이터 창과 분석 창 전환 탭 4. 데이터 원본 이름 5. 차원 6. 측정값 7. 집합 8. 매개 변수 9. 페이지 선반 10.필터 선반 11. 마크 선반 (마크 카드) - 색상, 크기, 레이블, 세부 정보, 12. 도구 설명 등의 속성 단추가 포함되어 있음 13. 열과 행 선반 14. 뷰 15. 퀵 필터 16. 범례(색상 범례) 아래는 태블로의 화면과, 태블로에 연결된 실제 엑셀파일간의 관계를 참고할 수 있는 사진입니다. 연결: 불러온 엑셀파일 시트: 엑셀의 각각시트가 나타남 오른쪽에 각각의 두 시트를 드래그하여 한 번에 볼 수 있습니다.
 [Tableau]의 기본적인 동작원리와 집계(Aggregate)
[Tableau]의 기본적인 동작원리와 집계(Aggregate)
○ 태블로의 기본적인 동작원리 1. 필드는 정성적인 값과 정량적인 값에 따라 차원과 측정값으로 구분 - 차원: 정성적 데이터(제품명, 날짜, 지리명 등), 분석 기준이 되는 값, 불연속형 데이터로 측정값을 쪼개어 보는 하나의 관점 - 측정값: 정량적 수치, 연속형 데이터로 집계가 되는 데이터 2. 측정값은 차원을 기준으로 집계되어 표현 ! - 집계란 합계, 평균, 중앙값, 카운트, 카운트(고유), 최소값, 최대값, 백분위수, 표준편차, 분산 등을 의미 - 측정값(숫자값)을 특정 기준(차원)으로 모으는 것을 의미합니다. 이때 반드시 집계 방법(합계, 평균, 최대값 등)이 지정되어야 하는데, 이를 집계 함수라고 합니다. - 만약 차원(문자데이터)가 숫자 값으로 인식되어 측정값으로 분류되어있는 경우 차원으로 ..